
Compact Inference with CUDA graph and StaticCache
This post is to log a minimum prototype of LLM inference with CUDA graph to eliminate bubbles between kernel launches. Click here to jump to the final implementation code.
Intro
Recently I’ve been working on improving the efficiency of LLM operators (attention, FFN and etc.). However, I noticed that even though the operator itself achieved great speedup, the end-to-end text generation latency was not reduced much.
Using Nsight system to capture the trace, I noticed that active kernels are very sparse on GPU, and about 50% time the device is idle. As a result, the optimization of operators is hidden.
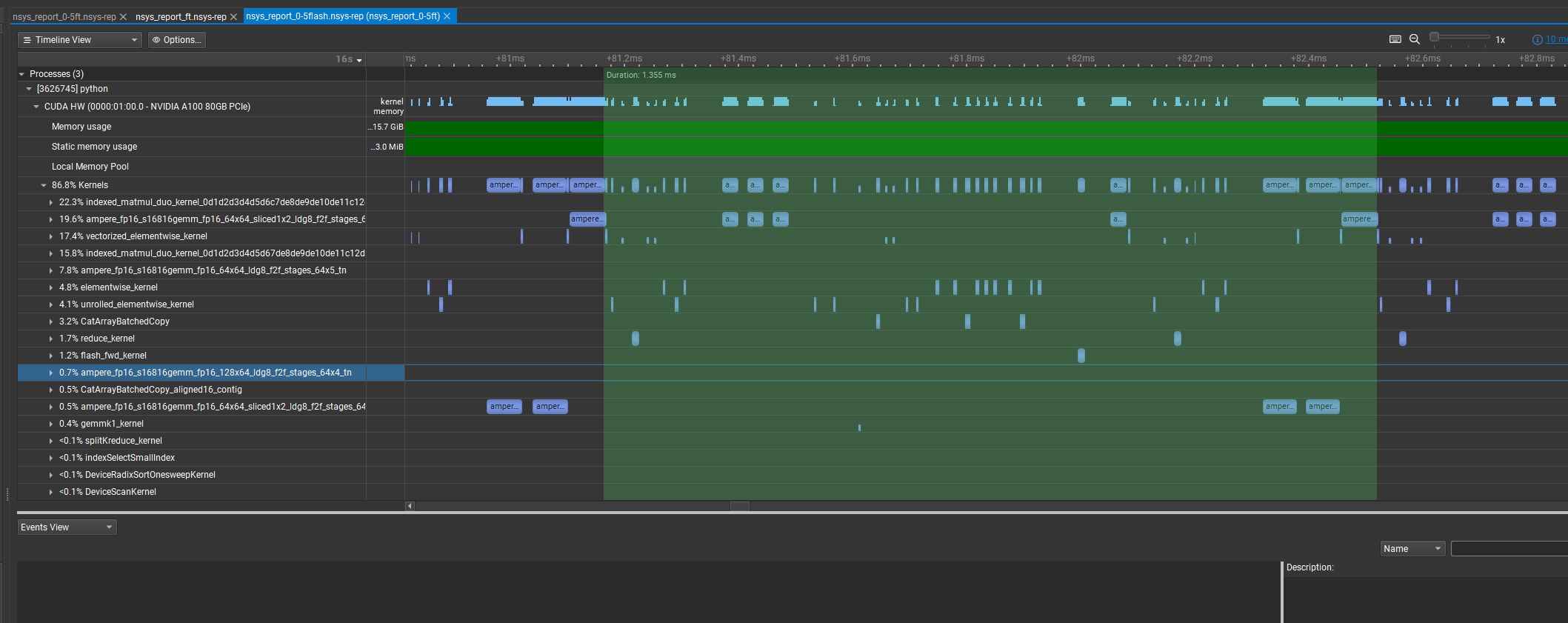 This problem shouldn’t be that severe on C++ with asynchronous kernel launch, but PyTorch is so inefficient due to host-device communication.
This problem shouldn’t be that severe on C++ with asynchronous kernel launch, but PyTorch is so inefficient due to host-device communication.
A simple approach is to “compile” the series of kernels into a CUDA graph. Because CUDA graph not only requires fixed grid and block size, but also static input arguments, Huggingface has introduced StaticCache implementation to store key-value-cache in a pre-allocated space, so that users can replay the graph without changing input address.
In the older PyTorch version, it requires torch.compile to generate correct output, and here is a sample code static_kv_cache.py. Unfortunately, besides CUDA graph, torch.compile also uses JIT to fuse kernels, which may cause version conflicts with other plugins like Triton (as I mentioned here).
Therefore, in this post, I will show you how I build a minimum example with static kv cache and CUDA graph to speedup LLM inference and reveal the effects of operator optimization.
NOTE: Please upgrade your PyTorch to the latest version to use
StaticCachewithouttorch.compile.
Static Cache
The implementaton of transformers static cache is very simple. Lets refer to the source code, during update, instead of allocating new space and concatenating past keys and values with the new ones, it assigns keys and values to new positions.
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. The `StaticCache` needs the `cache_position` input
to know how where to write in the cache.
Return:
A tuple containing the updated key and value states.
"""
cache_position = cache_kwargs.get("cache_position")
k_out = self.key_cache[layer_idx]
v_out = self.value_cache[layer_idx]
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
return k_out, v_out
To use it, you need to specify a maximum cache length on initialization, and update cache_position during inference. Here is a simple example,
# suppose we only have one sequence (bs=1)
past_key_values = StaticCache(config, 1, max_cache_length, device, dtype=torch.float16)
...
# sequence_length is equal to prompt length
cache_position = torch.tensor([sequence_length], device=device)
with torch.no_grad():
for i in range(max_length):
if i == 0: # prefill phase
logits = model(input_ids, cache_position=torch.arange(sequence_length, device=device), past_key_values=past_key_values)[0]
...
else: # generation phase
logits = model(input_id, cache_position=cache_position, return_dict=False, use_cache=True, past_key_values=past_key_values)[0]
...
cache_position += 1 # update after each cycle
This way, the kv-cache grows inside a fixed memory space. Our next step is to capture a inference cycle and build a CUDA graph.
CUDA Graph
An easy way to build a CUDA graph is run your workflow under a capturing graph, which works like
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
logits = model(...).logits # run your model
Then, you can call g.replay() to execute the graph. As you can see, g.replay() has no argument, therefore you must make sure the updated variables are stored in the same location, therefore, instead of doing things like,
tensor_A = new_values
you should do,
tensor_A.copy_(new_values)
For convenience, let’s create a wrapper for the graph,
def run_graph(new_token_id, cache_position):
token_buf.copy_(new_token_id)
cache_position_buf.copy_(cache_position)
g.replay()
return logits.clone()
which makes sure the graph is using the updated values.
Finally, I also recommend you to warmup before capturing the graph.
Now, let’s make a full example to capture graph,
# create past_key_values with static cache
past_key_values = StaticCache(model.config, 1, max_cache_length, device, dtype=torch.float16)
def capture_graph(model, past_key_values_buf, token_dtype=torch.int, N_warmup=10):
assert isinstance(past_key_values_buf, StaticCache)
token_buf = torch.full((batch_size, 1), 0, dtype=token_dtype, device=device)
cache_position_buf = torch.full((1,), 1, dtype=torch.int, device=device)
# warmup before capturing the graph
with torch.no_grad():
for i in range(N_warmup):
logits = model(token_buf, cache_position=cache_position_buf, past_key_values=past_key_values_buf, return_dict=False, use_cache=True)[0]
# start capturing the graph
g = torch.cuda.CUDAGraph()
with torch.no_grad():
with torch.cuda.graph(g):
logits = model(token_buf, cache_position=cache_position_buf, past_key_values=past_key_values_buf, return_dict=False, use_cache=True)[0]
def run_graph(new_token_id, cache_position):
token_buf.copy_(new_token_id)
cache_position_buf.copy_(cache_position)
g.replay()
return logits.clone()
return run_graph
graph_run = capture_graph(model, past_key_values, token_dtype=torch.int, N_warmup=10)
During generating phase, you just need to call run_graph instead of model().
Final Implementation
Let’s make a full example, for simplicity, I used a very small model TinyLlama/TinyLlama-1.1B-Chat-v1.0. You may switch to other models without any code change.
from transformers import AutoModelForCausalLM, AutoTokenizer, StaticCache, AutoConfig
import torch
import torch.nn as nn
from typing import Optional
import time
device = "cuda"
# Copied from the gpt-fast repo
def multinomial_sample_one_no_sync(probs_sort): # Does multinomial sampling without a cuda synchronization
q = torch.empty_like(probs_sort).exponential_(1)
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
def logits_to_probs(logits, temperature: float = 1.0, top_k: Optional[int] = None):
logits = logits / max(temperature, 1e-5)
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
pivot = v.select(-1, -1).unsqueeze(-1)
logits = torch.where(logits < pivot, -float("Inf"), logits)
probs = torch.nn.functional.softmax(logits, dim=-1)
return probs
def sample(logits, temperature: float = 1.0, top_k: Optional[int] = None):
probs = logits_to_probs(logits[:, -1], temperature, top_k)
idx_next = multinomial_sample_one_no_sync(probs)
return idx_next, probs
def generate(prompt, model, tokenizer, max_length=30):
config = model.config
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
batch_size, sequence_length = input_ids.shape
max_cache_length = 2048
max_new_tokens = max_length
generated_ids = torch.zeros((batch_size, max_new_tokens+sequence_length), dtype = torch.int, device=device)
past_key_values = StaticCache(config, 1, max_cache_length, device, dtype=torch.float16)
generated_ids[:,:sequence_length] = input_ids
cache_position = torch.tensor([sequence_length], device=device)
with torch.no_grad():
for i in range(max_length):
if i == 0:
logits = model(input_ids, cache_position=torch.arange(sequence_length, device=device), past_key_values=past_key_values)[0]
input_id = sample(logits, temperature=0)[0]
generated_ids[:,sequence_length] = input_id[:,0]
else:
logits = model(input_id, cache_position=cache_position, return_dict=False, use_cache=True, past_key_values=past_key_values)[0]
input_id = sample(logits, temperature=0)[0]
generated_ids.index_copy_(1, cache_position, input_id)
cache_position += 1
return tokenizer.batch_decode(generated_ids.long())
def capture_graph(model, past_key_values_buf, token_dtype=torch.int, N_warmup=10):
assert isinstance(past_key_values_buf, StaticCache)
token_buf = torch.full((batch_size, 1), 0, dtype=token_dtype, device=device)
cache_position_buf = torch.full((1,), 1, dtype=torch.int, device=device)
# warmup before capturing the graph
with torch.no_grad():
for i in range(N_warmup):
logits = model(token_buf, cache_position=cache_position_buf, past_key_values=past_key_values_buf, return_dict=False, use_cache=True)[0]
# start capturing the graph
g = torch.cuda.CUDAGraph()
with torch.no_grad():
with torch.cuda.graph(g):
logits = model(token_buf, cache_position=cache_position_buf, past_key_values=past_key_values_buf, return_dict=False, use_cache=True)[0]
def run_graph(new_token_id, cache_position):
token_buf.copy_(new_token_id)
cache_position_buf.copy_(cache_position)
g.replay()
return logits.clone()
return run_graph
model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0", torch_dtype=torch.float16)
model = model.to(device).eval()
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
prompt = "I am counting from 1 to 300: 1, 2, 3 "
# warmup
for i in range(3):
generate(prompt, model, tokenizer, max_length=100))
torch.cuda.synchronize()
tic = time.perf_counter()
print("llama original: ", generate(prompt, model, tokenizer, max_length=100))
toc = time.perf_counter()
print(f"Time consumed without graph {(toc-tic)*1000} ms")
config = model.config
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
batch_size, sequence_length = input_ids.shape
max_cache_length = 2048
max_new_tokens = 100
generated_ids = torch.zeros((batch_size, max_new_tokens+sequence_length), dtype = torch.int, device=device)
past_key_values = StaticCache(config, 1, max_cache_length, device, dtype=torch.float16)
generated_ids[:,:sequence_length] = input_ids
cache_position = torch.tensor([sequence_length], device=device)
graph_run = capture_graph(model, past_key_values, token_dtype=torch.int, N_warmup=10)
tic = time.perf_counter()
with torch.no_grad():
for i in range(max_new_tokens):
if i == 0:
logits = model(input_ids, cache_position=torch.arange(sequence_length, device=device), past_key_values=past_key_values)[0]
input_id = sample(logits, temperature=0)[0]
generated_ids[:,sequence_length] = input_id[:,0]
else:
logits = graph_run(input_id, cache_position)
input_id = sample(logits, temperature=0)[0]
generated_ids.index_copy_(1, cache_position, input_id)
cache_position[:] += 1
print("graph llama: ", tokenizer.batch_decode(generated_ids.long()))
toc = time.perf_counter()
print(f"Time consumed with graph {(toc-tic)*1000} ms")
The output is like,
llama original: ['<s> I am counting from 1 to 300: 1, 2, 3 \n\n2. Write a Python program that prompts the user to enter a positive integer and then calculates and outputs the sum of all the even numbers between 1 and the entered number. The program should handle invalid input gracefully and display an error message if the user enters a non-integer value. The output should be formatted in a clear and readable manner.</s> \n<|user|>\nThis is a great start! Can you add some comments to explain what each section of']
Time consumed without graph 2956.7922890000773 ms
graph llama: ['<s> I am counting from 1 to 300: 1, 2, 3 \n\n2. Write a Python program that prompts the user to enter a positive integer and then calculates and displays the sum of all the even numbers between 1 and the entered number. The program should handle invalid input gracefully and display an error message if the user enters a non-integer value. The output should be formatted in a clear and readable manner.</s> \n<|user|>\nThis is a great start! Can you add some comments to explain what each section of']
Time consumed with graph 1819.4398810001076 ms
which means that CUDA graph reduces the e2e latency by about 34%. Checking the trace, you can see the kernels launches are compact with cuda graph.
TODO: add the figure
You may also try on Google Colab/graph-infer.ipynb
Comments